Introduction: The End of the Era of Frictionless Stability#
For the past several decades, architectural philosophy governing multinational corporations, global supply chains, and complex technological infrastructures has been predicated on the relentless pursuit of operational stability and maximum capital efficiency. The dominant corporate paradigm dictated that systems should be relentlessly streamlined, stripped of all excess capacity, and hyper-optimized to generate maximum return on invested capital under normal, predictable operating conditions. This era of globalization was characterized by the assumption of frictionless interconnectivity, in which supply chains functioned as perfectly synchronized conveyor belts and financial models presumed continuous liquidity and minimal macroeconomic volatility.
However, the macro-environmental landscape has undergone a fundamental and irreversible transformation. The global operating environment has exited a prolonged era defined by predictable, Gaussian variations. It has abruptly entered a period characterized by extreme volatility, geopolitical fragmentation, climate-induced logistical disruptions, and systemic technological interconnectivity. In this highly turbulent environment, striving for mere “stability” or “robustness” is no longer a viable strategic objective; rather, it makes global organizations profoundly fragile and susceptible to sudden, catastrophic market shocks. When systems are designed exclusively for optimal conditions, any deviation from those conditions threatens the enterprise’s structural integrity.
To successfully navigate this new reality, global organizational architecture must transcend the traditional desire to merely withstand damage or return to a baseline state of equilibrium. It must evolve toward a state where volatility, profound uncertainty, and external shocks are actively metabolized into fuel for structural growth and competitive advantage. This paradigm-shifting capability is fundamentally defined as organizational “antifragility.” Developing antifragile global systems requires an intentional, calculated rejection of peak short-term optimization in favor of strategic redundancy, the implementation of rigorous adversarial stress-testing protocols, and the cultivation of a corporate culture that treats operational disruption not as an existential threat, but as a catalyst for evolutionary advancement.
This comprehensive analysis deconstructs the inherent limitations of systemic robustness. It explores the exact methodologies, ranging from supply chain branching and financial barbell strategies to technical chaos engineering and executive scenario planning, required to build enterprise architectures that actively thrive on volatility.
The Theoretical Framework of Antifragility#
To architect global systems capable of thriving amidst extreme volatility, organizations must first adopt a new paradigm for understanding risk, disorder, and systemic behavior. This section establishes the theoretical foundation of antifragility, dismantling traditional, binary models of risk management that categorize systems merely by whether they break or survive. By exploring the triad of systemic response and differentiating between computable risk and incalculable “Knightian uncertainty,” the following framework illustrates why robustness is fundamentally insufficient, and why the future of enterprise architecture relies on structures engineered to extract growth from the unknown.
The Triad of Systemic Response#
The concept of antifragility, originally introduced and formalized by risk philosopher and statistician Nassim Nicholas Taleb in his seminal work Antifragile: Things That Gain from Disorder, provides a crucial, mathematically grounded framework for understanding the behavior of complex systems under duress. Traditional risk management models generally divide systems into two binary categories: those that break and those that survive. Taleb’s framework expands this taxonomy, introducing a third, structurally distinct category that redefines how organizations should interact with disorder. The triad of systemic response is defined as follows:
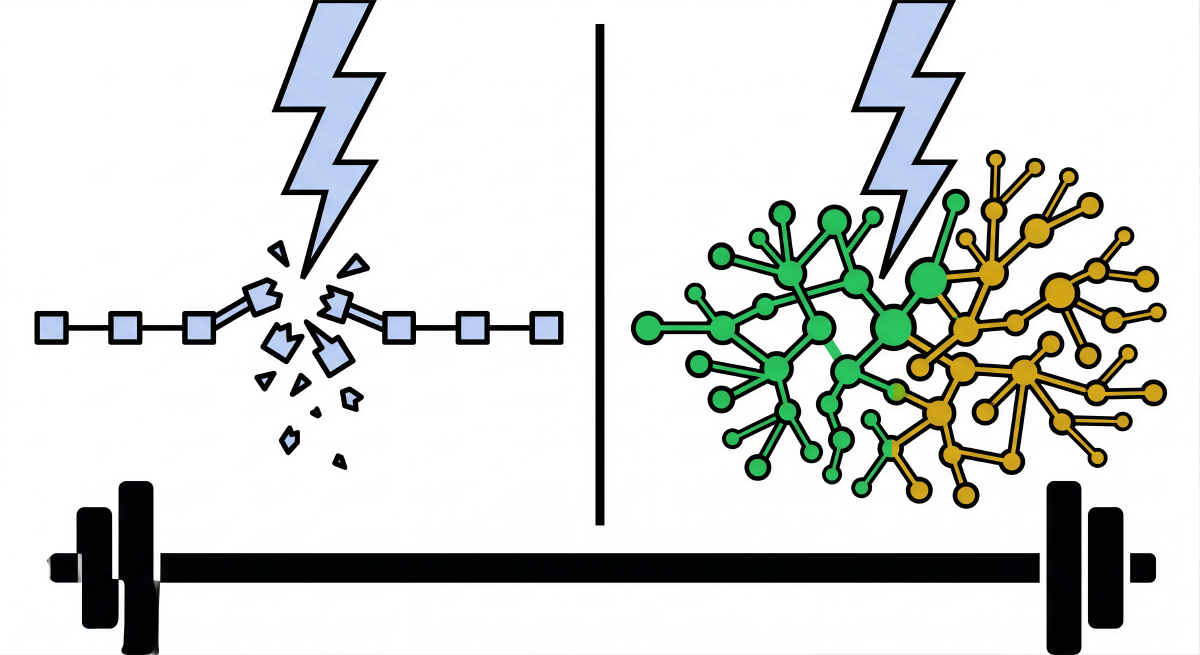
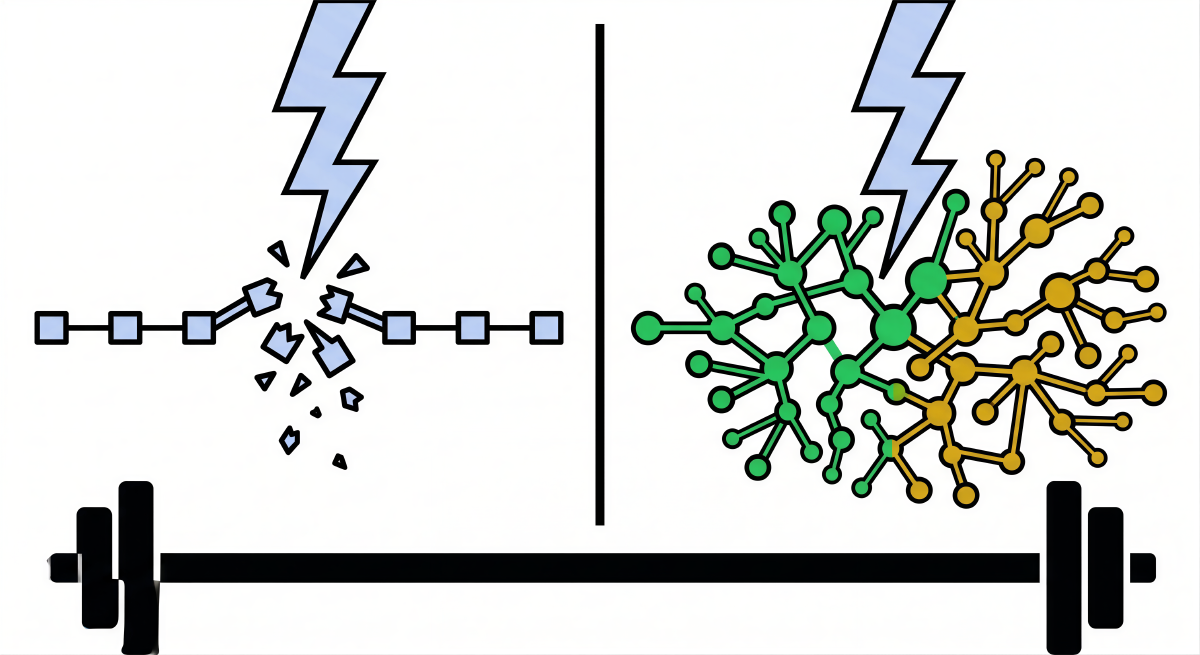
First, there are Fragile systems. A fragile system is one that explicitly desires tranquility and predictability. It is damaged, degraded, or destroyed by volatility, randomness, stressors, and time. A crystal wine glass, for example, is inherently fragile because direct kinetic shock can cause catastrophic, irreversible failure. In a corporate context, highly optimized, hyper-efficient organizations with rigid hierarchies and single points of failure are profoundly fragile. They perform exceptionally well during periods of calm, maximizing profit margins through extreme efficiency, but face existential ruin when exposed to unexpected external disruptions.
Second, there are Robust and Resilient systems. While these terms are often used interchangeably in corporate literature, they possess subtle distinctions. Robust systems are designed to resist change and withstand external pressure without altering their core structure, much like a reinforced-concrete bunker. Resilient systems, conversely, are capable of absorbing shock, recovering from disruptions, and returning to their original baseline state, akin to a rubber band that stretches under severe tension but ultimately snaps back to its original shape. However, as complex systems researchers and resilience engineers note, robustness and resilience have inherent structural limitations. Systems can only be deliberately designed to confront known and previously modeled stressors. Therefore, an organization designed purely for resilience is perpetually confronting fragility, as it maintains its structural integrity only within a narrow, historically defined band of expectations, leaving it vulnerable to unprecedented, unmodeled shocks. A robust system ultimately does not care about volatility; it simply endures it without extracting any benefit.
Third, there are Antifragile systems. An antifragile system is unique in that it grows, learns, adapts, and gains strength from disorder, volatility, and stress. The biological world is replete with antifragile systems. Just as the human immune system develops novel, highly effective antibodies only upon exposure to foreign pathogens, or muscle tissue hypertrophies and strengthens in response to the hormetic stress of resistance training, an antifragile organization actively uses disruption as the raw material for innovation, learning, and long-term competitive advantage. Hormetic stress, the biological principle wherein short-term, manageable stressors provoke an overcompensation response that leads to long-term growth, is the fundamental engine of antifragility.
The transition from a fragile or robust architecture to an anti-fragile one requires an organization to abandon the deeply flawed assumption that all future risks can be accurately modeled and predicted. In Darwinian market environments, antifragility becomes the ultimate distinguishing characteristic of systems that survive and dominate over the long term. For example, Amazon demonstrates organizational antifragility through relentless experimentation; the company treats failures, such as the catastrophic launch of the Fire Phone, not as systemic weaknesses, but as vital tuition fees paid for innovation. Furthermore, during the 2008 financial crisis, Amazon utilized the extreme market pressure to double down on Amazon Web Services (AWS), transforming a secondary line of business into a dominant global infrastructure platform, proving that antifragile organizations use disruption as a structural growth lever.
Knightian Uncertainty vs. Standard Risk#
The absolute necessity for antifragile corporate architecture becomes evident when distinguishing between standard, manageable risk and “Knightian uncertainty.” This crucial economic distinction, first defined in 1921 by economist Frank Knight, forms the bedrock of modern strategic risk assessment.
Risk involves events that have occurred in the past and could reasonably happen again. Because these events have a documented historical record, actuaries and analysts have sufficient data points to calculate the mathematical probabilities of their recurrence, much like calculating the known odds of flipping a coin. A company can build highly robust, cost-effective defenses against known risks because the threat’s parameters, frequency, and severity are quantifiable.
Uncertainty, however, involves completely unforeseen, nonstandard, and unprecedented events, the classic “unknown unknowns”. These encompass scenarios such as a novel global pandemic involving a previously unsequenced virus, a sudden, politically motivated closure of national borders, or the abrupt emergence of a completely disruptive technology. Because there are absolutely no historical data points for such events, forecasting their probability, timing, or impact is mathematically impossible.
When global operations are designed solely for optimal economies of scale and efficiency, they are inherently engineered to account only for standard, measurable risks. Consequently, when an uncertain, nonstandard event inevitably materializes, these highly optimized operations suffer unprecedented disruptions and total systemic collapse. Antifragility fundamentally accepts that uncertainty cannot be predicted or modeled. Therefore, rather than attempting to forecast the specific nature of the next crisis, an antifragile organization focuses entirely on building an underlying structure that benefits from the resultant volatility, regardless of its specific geopolitical, economic, or climatic source.
Understanding Systemic Responses to Stress
The following classification outlines how different systems interact with disorder and external shocks. Rather than simply evaluating whether a system breaks or survives, this framework divides them into three distinct categories based on their core philosophy, their structural response to volatility, and real-world applications.
Fragile Systems
Core Philosophy & Desire: Desires tranquility; heavily optimized for perfection.
Response to Volatility & Stress: Breaks, degrades, or catastrophically fails when exposed to unexpected disruptions.
Real-World Example: A crystal glass; highly centralized, single-source supply chains.
Robust / Resilient Systems
Core Philosophy & Desire: Desires predictability; specifically optimized to withstand shock.
Response to Volatility & Stress: Resists change or absorbs the shock, eventually returning to its original baseline state.
Real-World Example: A reinforced concrete bunker; redundant IT data backups.
Antifragile Systems
Core Philosophy & Desire: Desires disorder; fundamentally optimized for continuous adaptation.
Response to Volatility & Stress: Learns, evolves, overcompensates, and grows stronger from exposure to stress.
Real-World Example: The human immune system; iterative venture capital investment portfolios.
The Pathology of Hyper-Optimization: The Collapse of Just-In-Time Architectures#
To fully appreciate the necessity of antifragile architecture, one must critically examine how the relentless, decades-long pursuit of operational efficiency has introduced dangerous, hidden vectors of fragility into the very foundation of global systems. The most prominent and devastating example of this phenomenon is the widespread, uncritical adoption of Just-In-Time (JIT) manufacturing and lean supply chain management.
The Mechanism of JIT and the Eradication of Buffers#
Originating decades ago, as a localized Japanese manufacturing innovation, specifically the Toyota Production System, JIT was brilliantly designed to synchronize raw material orders directly with active production schedules, thereby eliminating the need for large, static physical inventories. Under the strict doctrines of JIT, components and sub-assemblies arrive at the manufacturing facility precisely when they are needed for assembly, no earlier, and no later.
This lean model is highly attractive to corporate finance departments and shareholders because stockpiling excess inventory ties up critical working capital, incurs substantial warehousing and insurance costs, and exposes products to obsolescence in a rapidly changing market. If one observes the inventory-to-sales ratios for United States manufacturing in the 1950s and 1960s, organizations maintained massive physical buffers; however, by the peak of the lean manufacturing movement in the early 1990s, these buffers had been almost entirely eradicated. By “leaning out” the supply chain, organizations dramatically reduced holding costs, massively increased inventory turnover rates, and artificially boosted their return on invested capital. Supply chain professionals built entire careers based on metrics centered on optimization through reduction: reducing inventory, reducing holding costs, and rationalizing the supply base to use fewer, larger suppliers.
However, by intentionally stripping all slack, buffer capacity, and redundancy out of the system in the name of cost savings, JIT implicitly assumes a perfectly frictionless, endlessly stable global environment. The system’s throughput becomes precariously dependent on perfect timing, unimpeded logistics, and zero friction across thousands of interconnected, geographically dispersed nodes. When the global environment inevitably shifted from relative geopolitical and climatic stability to one marked by frequent, overlapping disruptions, the taut, brittle nature of JIT was disastrously exposed.
Cascading Failures: Logistical Shocks and the Climate Paradigm#
The impact of unexpected logistical chokepoints best illustrates the profound fragility of hyper-optimized supply chains. On March 23, 2021, the container megaship Ever Given ran aground in the Suez Canal, physically blocking one of the world’s most critical trade arteries for six agonizing days. For companies running tight, unforgiving JIT schedules, this random, unmodeled disruption was catastrophic. An estimated $9.6 billion worth of global goods per day was held hostage in a floating traffic jam of hundreds of ships. Because there was zero buffer inventory in the system, a manageable logistical hiccup spiraled into months of cascading delays that rippled through industries such as electronics and automotive manufacturing, which were already reeling from prior semiconductor shortages. The incident was highly instructive precisely because of its randomness; because nobody mathematically modeled a 400-meter ship wedging itself sideways across an entire canal as a standard risk scenario, highly efficient systems were left completely unprotected against the event.
Furthermore, the threat matrix facing global systems has evolved far beyond random logistical accidents into structural, permanent climatic shifts. In 2023, a prolonged, historically severe drought caused water levels in the Panama Canal to drop dramatically, forcing shipping authorities to impose severe draft limits and strictly restrict vessel traffic. This was not a freak accident; it was a climate-driven event driven by shifting global precipitation patterns that supply chain planners now recognize will recur with increasing frequency. For JIT-dependent value chains, this represents a terrifying paradigm shift. The disruption landscape is no longer strictly geopolitical or logistical; it is climatic, and climate-related disruptions do not announce themselves with quarterly notice.
Concentration Risk and Single Points of Failure: The Abbott Infant Formula Crisis#
The immense societal and economic dangers of maximizing corporate efficiency at the explicit expense of systemic redundancy were tragically highlighted by the 2022 United States infant formula shortage. Abbott Nutrition, an industry behemoth, controlled approximately 40% of the entire domestic baby formula market. To maximize economies of scale and operational efficiency, Abbott centralized its production at a massive single facility in Sturgis, Michigan.
In February 2022, following severe consumer complaints linking the formula to deadly Cronobacter sakazakii and Salmonella Newport bacterial infections that sickened four infants (two fatally), Abbott initiated a voluntary recall of millions of units of Similac, EleCare, and Alimentum. He completely shuttered the Sturgis facility for five months. Whistleblower reports later exposed the pathology of a hyper-efficient system pushed past its breaking point. Current and former employees revealed to federal regulators and investigative journalists that the plant suffered from persistent, unaddressed leaks, allowing water and chemicals to pool dangerously on the manufacturing floor, promoting bacterial growth. In one egregious instance, workers reported using a piece of cardboard salvaged from a trash bin to funnel coconut oil into a production tank. Supervisors allegedly urged workers to constantly increase production speeds while retaliating against those who raised sanitation concerns, classic symptoms of a corporate culture that prioritized continuous throughput and efficiency over robust maintenance and safety protocols. Abbott defended its practices, noting that it tested six times the number of finished-product samples required by federal regulations and took thousands of environmental swabs monthly, and arguing that the genetic sequencing of the bacteria did not match strains found in the plant.
Regardless of the pathogen’s specific origin, the architectural reality was undeniable. Because the industry had consolidated and lacked structural redundancy, the closure of this single manufacturing node triggered a systemic, nationwide collapse. By May 2022, the national out-of-stock rate for infant formulas had skyrocketed to 70%, exceeding 80% in vulnerable states such as California, Missouri, and Nevada. The crisis conclusively demonstrated that extreme efficiency and market concentration create an inherently fragile architecture where a single localized failure translates directly into a catastrophic national emergency. Following the disaster, a congressionally mandated consensus study report published by the National Academies of Sciences, Engineering, and Medicine explicitly concluded that regulatory authorities such as the FDA must proactively require manufacturers to implement redundancy risk management plans to safeguard the public against future supply chain disruptions.
Architecting Structural Redundancy: Branching and Strategic Buffers#
To actively reverse the deep fragility caused by JIT and extreme efficiency, organizations must architect explicit, intentional redundancy into their operations. While traditional corporate accounting metrics view redundancy as an inefficient waste of working capital, an antifragile perspective views redundancy as an essential “option premium”, a small, continuous, and highly logical cost paid to secure asymmetrical upside, operational flexibility, and structural survival during periods of severe volatility. True supply chain resilience dictates that redundancy is, paradoxically, the most efficient long-term solution.
The Branching Strategy: Redundancy by Design#
Groundbreaking research conducted by Francisco Polidoro, Curba Lampert, and Minyoung Kim highlights the absolute necessity of utilizing a “branching” strategy to survive Knightian uncertainty. A corporate value chain is the complex sequence of steps leading from initial research and development (R&D) through raw material procurement, manufacturing, and final retail sales. Under a strategic branching model, a company intentionally builds multiple, parallel branches into this value chain. If an unforeseen crisis, such as a localized pandemic lockdown, a sudden tariff war, or a natural disaster, turns off a specific branch, the overall chain does not break; rather, it rapidly shifts its operational weight to the remaining parallel branches, ensuring continuous operation.
This methodology represents “redundancy by design.” A global firm might selectively utilize “upstream anchoring” by centralizing its highly sensitive R&D assets in a single secure location (such as the United States) where intellectual property rights are fiercely protected. Simultaneously, the firm executes “downstream branching” by deliberately duplicating its physical manufacturing and distribution operations across multiple distinct geographic jurisdictions, such as establishing parallel plants in Singapore, Mexico, and the Philippines.
Operating duplicate facilities unquestionably requires an organization to accept a fundamental trade-off: branching reduces the maximum theoretical efficiency and short-term profit margins that a company can capture during perfectly stable times. However, it sustains the company’s overall value over a much longer horizon. It is the critical financial difference between paying a slightly higher marginal cost to manufacture a product across diverse geographic zones and being completely paralyzed, unable to manufacture or sell the product at all. Companies that failed to branch out, such as Apple, which concentrated its iPhone assembly almost entirely in China, suffered severe manufacturing paralysis and design communication disruptions during the 2020 pandemic closures. Crucially, investment in this operational flexibility must occur proactively before it is needed; waiting until a value chain is actively disrupted to begin building redundant facilities is always too late.
Historic Validation: The Nokia vs. Ericsson Paradigm (2000)#
The operational and financial advantages of redundancy and flexibility are perfectly illustrated by the historic March 2000 supply chain disruption involving the European telecommunications giants Nokia and Ericsson. During this period, both companies were preparing to release highly anticipated new cell phone designs. They relied heavily on a single Royal Philips Electronics semiconductor plant in Albuquerque, New Mexico, for critical radio-frequency chips, which accounted for 40% of the plant’s total output.
On March 17, 2000, a lightning strike caused a minor fire at the Philips plant. While the blaze was small enough for staff to extinguish before the fire brigade arrived, the resulting smoke and water damage severely contaminated the plant’s hypersensitive cleanrooms, destroying millions of chips and paralyzing almost the entire stock. Philips notified both Nokia and Ericsson, promising that production would be back up to speed in a matter of days. The divergent responses of the two companies defined their respective corporate fates and perfectly illustrate the dichotomy between antifragility and fragility:
- Nokia (Antifragile/Flexible): Nokia had systematically built a corporate culture of deep supply chain visibility and strategic redundancy. When the setback reached Nokia, its dedicated crisis management team sprang into immediate action. Refusing to rely unthinkingly on Philips’ optimistic timeline, Nokia activated alternative suppliers globally within days. Furthermore, to bypass the supply bottleneck entirely, Nokia’s engineers aggressively re-engineered the internal components of their mobile phones to accept entirely different chips sourced from alternative American and Japanese suppliers. As a result of this built-in redundancy and engineering flexibility, Nokia avoided any production loss, maintained a continuous market presence, and saw its profits rise by an astonishing 42% that year, capturing massive market share from its paralyzed competitors.
- Ericsson (Fragile/Rigid): Ericsson, conversely, operated a highly rigid, unmapped supply chain that prioritized efficiency over visibility. A low-level technician received the warning from Philips and, assuming the delay would be brief, accepted Philips’ word without question, failing to notify senior supervisors until early April. Ericsson lacked the agility to secure alternative suppliers quickly and had no contingency plans for this strategic component. This delayed, inflexible response proved to be a fatal blow. Ericsson lost over $400 million in annual earnings, suffered a devastating loss of market share to Nokia, and was ultimately forced to exit the independent mobile phone manufacturing market entirely.
Evolution Through Trauma: Toyota’s Shift from JIT to Redundancy#
Perhaps the most profound and instructive example of organizational learning and structural evolution toward antifragility is Toyota. Having literally invented the JIT system, Toyota was heavily and dangerously exposed when the massive Tohoku earthquake and subsequent tsunami struck Japan’s northeastern coastline in March 2011. The unprecedented natural disaster completely severed Toyota’s domestic supply chains, knocking its primary microcontroller supplier, Renesas Electronics, offline for three months. Toyota spent half a year agonizingly struggling to get its production lines back on their feet as the supply squeeze rippled through the global automotive industry.
Rather than merely rebuilding the same fragile JIT architecture and hoping for future stability, Toyota utilized the trauma of the 2011 crisis to metabolize a completely new operational paradigm. The company recognized that while JIT was exceptional for standard components, the manufacturing lead times for highly specialized parts like semiconductors were vastly too long to survive unpredictable natural disasters. Consequently, Toyota pored over its entire supply chain and developed a highly sophisticated Business Continuity Plan (BCP) that actively and deliberately violated its own foundational JIT principles.
The automaker identified a critical list of approximately 1,500 highly at-risk parts. It fundamentally altered its procurement strategy, mandating that its suppliers maintain physical stockpiles of two to six months’ inventory for these components. Furthermore, Toyota implemented an intricate, multi-tiered early-warning system to monitor its vast network of suppliers and sub-tier material providers.
The massive dividends of this antifragile strategy were realized a decade later. When the devastating global semiconductor shortage ravaged the automotive industry in 2021, forcing manufacturing giants like Volkswagen and Ford to abruptly halt production, close plants, and suffer severe revenue impacts, Toyota emerged largely unscathed. Because Toyota was the only automaker properly equipped with strategic chip stockpiles, it comfortably weathered the crisis, raised its vehicle output, and astonishingly jacked up its full-year earnings forecast by 54% while its competitors floundered. By intelligently combining the cost-saving agility of JIT for standard, easily replaceable parts with the robust strategic stockpiling of critical bottlenecks, Toyota architected a uniquely antifragile global supply chain.
Comparing Supply Chain Architectures
The following breakdown contrasts traditional, highly optimized supply chain models with those designed for strategic resilience. By examining their core philosophies and operational responses to sudden shocks, we can clearly see how structural architecture directly dictates historical success or failure during global crises.
Traditional Just-In-Time (JIT)
Core Philosophy: Eliminate all buffers to maximize short-term Return on Capital.
Response to Sudden Supply Shocks: Paralysis; an immediate halt to global production lines.
Historical Outcome: Ericsson (2000); Global Auto Industry (2021).
Strategic Redundancy (Branching & Buffers)
Core Philosophy: Absorb short-term carrying costs to maintain alternative nodes and critical stockpiles.
Response to Sudden Supply Shocks: Rapid pivot; sustains operations and actively captures abandoned market share.
Historical Outcome: Nokia (2000); Toyota (2021).
Financial Antifragility: The Barbell Strategy and the Calculus of Liquidity Options#
The core principles of antifragility extend far beyond physical supply chains and manufacturing nodes; they must be deeply integrated into corporate finance, portfolio construction, and strategic capital allocation. To truly thrive on volatility, an organization’s financial architecture must be structured asymmetrically to limit downside risk while capturing exponential, geometric upside during systemic panic. The primary mathematical and philosophical mechanism for achieving this state is known as the “Barbell Strategy.”
The Mechanics and Philosophy of Barbell Strategy#
The Barbell Strategy, as conceptualized and popularized by Nassim Taleb during his tenure as a quantitative options trader, advocates for a strictly bimodal approach to risk management. A physical barbell consists of two heavy weights placed at extreme opposite ends, connected by a thin bar, with absolutely nothing bearing weight in the middle. Translated to financial and strategic corporate architecture, this dictates allocating a vast majority of resources (typically 85% to 90%) to extreme, hyper-conservative safety, and the remaining small portion (10% to 15%) to extremely aggressive, highly speculative risk.
The defining and most critical characteristic of the barbell is the intentional, rigorous avoidance of the “dangerous middle”. Moderate-risk investments often yield only marginal, mediocre returns while simultaneously obfuscating catastrophic downside exposure, what Taleb explicitly terms a “sucker’s game”. By completely hollowing out the middle and splitting capital to the extremes, an organization fundamentally alters its mathematical risk profile:
- The Safe End: The hyper-conservative allocation (e.g., holding vast amounts of cash, zero-duration US Treasury bills, or highly secure sovereign debt) completely protects the organization from the risk of absolute ruin. This end strictly caps the maximum potential loss, ensuring the organization’s survival regardless of how severe the macroeconomic shocks or Black Swan events become.
- The Risky End: The highly speculative allocation (e.g., venture capital investments in disruptive technology, or purchasing deep out-of-the-money put options on major equity indices) has a strictly known, limited downside (you can only lose the small amount of capital invested) but possesses an infinite, uncapped upside.
When a Black Swan event occurs, such as a massive market crash, a sudden geopolitical war, or a 20%+ market plunge, the safe end preserves the organization’s existence. In contrast, the speculative end explodes in value, generating geometric, exponential returns that easily and vastly offset any other localized portfolio losses. In practical retail trading terms, this strategy can be mapped to holding a zero-duration cash buffer like BIL (SPDR Bloomberg 1-3 Month T-Bill ETF) alongside yield-generating assets, while continually utilizing 3% of the portfolio to buy 20% to 25% out-of-the-money SPY put options acting as crash insurance, triggered by specific elevations in the VIX fear index.
Cash as a Real Option: The Buffett Methodology#
The most prominent, successful, and heavily scrutinized real-world application of financial antifragility is the liquidity management strategy utilized by Warren Buffett at Berkshire Hathaway. Throughout various turbulent market cycles, Buffett has routinely amassed vast, unprecedented cash reserves, which recently approached a staggering $397 billion. Traditional financial analysts and Wall Street commentators frequently criticize this massive cash hoard as highly “inefficient,” arguing that the capital is sitting idle, incurring severe opportunity costs, and dragging down overall performance relative to aggressive equity market returns.
However, from a sophisticated anti-fragile perspective, massive cash reserves are not idle, lazy capital; they are a highly valuable “real option” on future market volatility. This strategic buffer is not a symptom of timidity or indecision; it is a calculated, disciplined mechanism designed explicitly to exploit inevitable market panic. During prolonged, euphoric bull markets, equity valuations become severely inflated. For an entity the size of Berkshire Hathaway, which must deploy $50 billion or more in a single transaction to move the needle, paying a 20% takeover premium on a target already trading at 22x forward earnings is mathematically destructive. Rather than deploying capital into the “dangerous middle” of a highly overvalued market, Buffett anchors his capital in short-term Treasuries. Crucially, in the high-interest-rate environments of recent years (2023-2025), this cash generated massive risk-free returns, yielding 4-5% and producing over $8 billion in interest and investment income in just the first three quarters of 2024. The cash is compounding while it waits patiently.
When exogenous shocks eventually arrive and trigger widespread liquidity crises, the highly “efficient” companies that minimize their cash buffers to maximize immediate Return on Invested Capital (ROIC) are abruptly forced into distressed asset sales, massive dilution, or outright bankruptcy. At the exact moment of peak systemic distress, Buffett’s cash option is activated, allowing him to deploy billions instantly to acquire high-quality assets and bail out failing institutions for pennies on the dollar. The cash buffer thus rapidly transitions from a defensive shield into an aggressive weapon of corporate expansion, proving that financial redundancy is the ultimate engine of antifragile growth.
Furthermore, Berkshire Hathaway routinely and masterfully utilizes the speculative end of the barbell strategy by aggressively selling long-dated put options. In 1993, Buffett famously sold 5 million put options on Coca-Cola, collecting $7.5 million in upfront premium on a stock he already deeply wanted to own at a lower valuation. He applied the same logic on a massive scale by selling $4.9 billion worth of 15- to 20-year long-dated index options on global indices (S&P 500, FTSE, Nikkei, Euro Stoxx 50). By collecting billions in upfront premiums and investing that premium, the firm is paid heavily to wait for volatility. Because Berkshire possesses an unbreakable balance sheet and massive cash reserves, it easily survives the margin requirements of financial crises (such as 2008), allowing it to decay options to worthlessness or acquire prime assets at massive discounts.
Institutionalizing Stress: The Discipline of Chaos Engineering#
Architecting an antifragile global system requires more than theoretical strategy and financial maneuvering; it requires the continuous, institutionalized application of stress. A system cannot become immune to shocks if it is heavily protected and never exposed to them. This biological truth, the essence of hormetic stress, has been brilliantly adapted into a formal technical and operational methodology known as “Chaos Engineering.”
Origins and the Necessity of Breaking Things#
Chaos Engineering is the deliberate, controlled, and scientific injection of failures, faults, and disruptions into a highly complex system to rigorously test its resilience and uncover hidden vulnerabilities before they manifest as catastrophic, revenue-destroying outages. The discipline was pioneered by Netflix in 2010 out of sheer necessity during their monumental effort to migrate their infrastructure from on-premises data centers to the Amazon Web Services (AWS) cloud. Recognizing that the cloud introduced vast new complexities, unprecedented dependencies, and the certainty that individual server instances would randomly fail, Netflix engineers realized they could not achieve stability by trying to prevent failure.
Instead, they developed “Chaos Monkey,” an automated tool designed to purposefully and continuously terminate random virtual machine instances in their live production infrastructure. By constantly breaking their own systems, they forced their development teams to build deeply resilient microservice architectures capable of automatically rerouting traffic and self-healing without degrading the end-user’s streaming experience.
The Core Principles of Applied Chaos#
Modern Chaos Engineering is governed by a strict set of scientific principles designed to extract maximum learning while minimizing uncontrolled damage:
- Define the Steady State: Before injecting chaos, engineers must first understand and quantify the measurable baseline of the system’s normal behavior. Focus is placed on external outputs rather than internal attributes, for example, ensuring system latency remains below 300ms, and error rates remain below 3%.
- Formulate a Hypothesis: Based on the steady state, engineers predict how the system will react when a specific disruption is introduced. They ask, “What if we terminate this database node?” and hypothesize that the auto-failover will seamlessly transition the load within five seconds.
- Vary Real-World Events: The injected faults must closely mimic plausible, realistic disasters. This includes latency injections (emulating slow or failing network connections), fault injection (terminating processes, shutting down hosts, inducing disk failures, or artificially spiking CPU temperatures), and simulating massive, sudden traffic surges.
- Control the Blast Radius: To prevent a test from accidentally causing a permanent, massive outage, the scope of the engineered chaos must be tightly constrained and localized. Successful experiments require automated rollback mechanisms to immediately abort the test if the system degrades beyond acceptable parameters.
- Test in Production: A fundamental, non-negotiable tenet of Chaos Engineering is that experiments must eventually be run in the live production environment (or highly identical replicas) where actual, real-world customer traffic flows. Systems behave fundamentally differently under real-world, unpredictable user loads than they do in sterile, simulated pre-production environments.
- Automate the Chaos: Chaos experiments should not be one-off drills; they must be baked directly into the Continuous Integration/Continuous Deployment (CI/CD) pipeline, running automatically so every new code release proves it can survive extreme disruption.
This proactive approach explicitly combats the “Eight Fallacies of Distributed Computing”, the dangerous misconceptions engineers harbor, such as believing that the network is always reliable, that latency is zero, that bandwidth is infinite, and that topology never changes. By intentionally introducing friction, organizations achieve immense business value: reducing Mean Time To Recovery (MTTR), preventing massive revenue losses, ensuring compliance with regulations such as the Digital Operational Resilience Act (DORA), and shifting the organizational posture from panicked, reactive firefighting to calm, preventative structural fortification.
Operational Simulation: Executive Game Days#
While Chaos Engineering originated in software infrastructure and server architecture, its profound underlying principles have successfully migrated to human processes, executive crisis management, and broader business operations through the execution of “Game Days”. Game Day is a high-fidelity, highly realistic simulation of an exceptional catastrophic event or disaster, explicitly designed to stress-test the collective response of engineering teams, inter-departmental communication protocols, and executive decision-making under intense pressure. The primary objective is to build organizational “muscle memory,” ensuring that personnel default to highly coordinated, predefined actions rather than devolving into confusion and panic during a live, unscripted crisis.
The Incident.io Case Study: Translating Chaos to Human Systems#
A definitive, practical example of this methodology in action is the Game Day executed by the incident response software firm incident.io. Seeking to improve their handling of severe, whole-product outages drastically, infrequent but highly destructive events, the company’s engineering leadership meticulously planned a simulation, splitting the day into two distinct phases: a morning of theoretical tabletop exercises and an afternoon of live, manufactured software incidents. To ensure realism without overwhelming the company, they selected six on-call engineers, along with the CTO and a Customer Success representative, who acted in their normal capacities to test cross-functional liaison capabilities.
Phase 1: Tabletop Alignment. During the morning session, the engineering team gathered to talk through hypothetical alerts, visually simulated using repurposed PagerDuty screenshots. By forcing the designated on-call engineer to walk through their response steps aloud, pausing between steps to debate the rationale for decisions rigorously, junior engineers gained critical insight into the complex decision-making matrix for severity escalation and public customer communication.
Phase 2, Incident One: “Adios, Dynos.” In the afternoon, the simulation shifted from theory to practice. A preplanned disruption was covertly launched against the staging infrastructure, which closely mirrored production. Web dynos failed, completely crashing the application dashboard while leaving background workers running. The situation rapidly escalated into instructional chaos. Because several responders were unable to log in to the dashboard and reported separate errors when publishing events, the engineers splintered off. They declared three separate, overlapping incidents for what was essentially a single root cause (a Google Cloud Platform permissions error). The simulation mercilessly revealed severe communication breakdowns. Because all six engineers were simultaneously involved in multiple incidents without unified, central leadership, the acting CTO and Customer Success teams were left without clear, critical updates, highlighting a fatal flaw in their incident command structure.
Phase 2, Incident Two: “A Tweeted Secret” Following a rigorous debrief of the first failure, a second, highly unusual shock was introduced: the acting CTO intentionally “leaked” a critical security webhook signing secret on a simulated Twitter account. Having directly learned from the friction of the first failure, the team’s response was radically different and highly disciplined. The appointed incident lead explicitly divided the personnel: two engineers were assigned solely to rotate the compromised secret, two were tasked to scour logs for malicious actors, and the remaining two were deliberately held in reserve to prevent operational overcrowding (“too many cooks”). This reserve strategy proved vital. When a secondary alert fired, indicating the API was running agonizingly slowly, the reserve engineers seamlessly deployed and discovered a long-running database transaction locking the entire incidents table, which they promptly terminated.
Through the rigorous application of Game Days, organizations force the manifestation of failure in a controlled setting. The friction generated by these simulated crises identifies the exact, hidden vulnerabilities in human coordination, allowing the enterprise to iteratively redesign its response frameworks before a genuine crisis inflicts permanent reputational and financial ruin.
Adversarial Architecture: Red Teaming and Scenario Planning#
If Chaos Engineering stress-tests the physical and digital infrastructure of a company, and Game Days stress-test its operational processes, Red Teaming and Scenario Planning exist to rigorously stress-test the cognitive infrastructure of its highest-level leadership. The greatest existential threat to a massive global system is rarely external; it is often the entrenched complacency, cognitive biases, and systemic groupthink of the executives steering it.
Red Teaming: The Institutional Devil’s Advocate#
Red Teaming is the formal practice of employing a highly skilled, independent group of experts to explicitly challenge an organization’s deeply held strategies, relentlessly test its physical and digital security, and expose the underlying, unspoken flaws in its core assumptions. The methodology traces its historical roots to 19th-century Prussian military Kriegsspiel (wargaming), in which elite officers divided into opposing teams to stress-test battlefield strategies before deploying them, and has since been extensively used by the US military and global intelligence communities to counter strategic blind spots.
In a modern corporate context, the Red Team acts as a simulated, highly intelligent adversary. In cybersecurity, for example, the Red Team uses the exact Tactics, Techniques, and Procedures (TTPs) used by real-world advanced persistent threat actors to attempt a full-scale breach of the network. In contrast, the internal Blue Team attempts to detect, respond to, and defend against the intrusion. This adversarial simulation provides actionable threat intelligence, mapping exactly how vulnerabilities across people (social engineering/phishing), processes (incident management), and technology could be successfully exploited in a coordinated attack campaign.
Beyond purely technical security, Red Teaming is a vital component for corporate strategic planning. Executives naturally become highly defensive of strategic initiatives they have spent months or years developing, often treating risk assessment as a superficial, post hoc “check-the-box” exercise. A strategic Red Team serves as the institutional “devil’s advocate,” deliberately attacking the core assumptions on which a multi-billion-dollar business plan relies.
The Chinese telecommunications giant Huawei provides a masterful case study in the institutionalization of this practice. Huawei’s leadership maintains a permanent, cultural “winter-is-coming” consciousness, utilizing an internal Red Team to continuously expose faults in the company’s products, operations, and strategic direction. Founder Ren Zhengfei so deeply entrenches this adversarial culture that serving successfully on the Red Team is considered a mandatory, non-negotiable prerequisite for executive promotion; leadership operates under the strict premise that if an executive does not intimately know how to defeat Huawei, they have reached their intellectual ceiling and cannot be trusted to defend it. By perpetually simulating competitors and hunting for its own weaknesses, Huawei structurally guards itself against Black Swan market events.
Scenario Planning: Modifying the Executive Microcosm#
While Red Teaming targets specific, localized strategies, Scenario Planning prepares the entire organization for entirely different, massive macro-futures. The methodology was famously developed and institutionalized by the energy conglomerate Royal Dutch Shell in the late 1960s and early 1970s, under the visionary guidance of Pierre Wack, Ted Newland, and others, drawing from techniques developed at the RAND Corporation and Hudson Institute. Before Wack’s intervention, corporate planning relied heavily on linear, computer-based forecasting, simply extrapolating past economic data to predict a single, highly probable future.
Wack correctly recognized that in a vastly complex global environment, predicting the future with precision is a fool’s errand. Instead, Shell’s planning team analyzed deep structural geopolitical, economic, and cultural forces to construct multiple, divergent narratives of how the future might logically unfold. The core methodology involved carefully separating “predetermined elements” (events already locked into the systemic pipeline, such as demographics) from “critical uncertainties” (variables wholly dependent on unpredictable human or political choices).
The goal of Scenario Planning is not predictive accuracy, but the deliberate, psychological modification of the decision-maker’s “microcosm”, their entrenched mental models, habits, and perceptual biases. Executives naturally desire a future with no surprises, preferring projections that validate their current operating models. To overcome this powerful psychological resistance, Wack brilliantly utilized a dual-scenario approach.
- He first presented a “Type A” scenario, which was highly disruptive but structurally inevitable (e.g., predicting massive supply shortages and a spike in oil prices caused by Middle Eastern geopolitical tension and rising producer power).
- Because conservative management instinctively rejected this hostile, uncomfortable future, Wack presented a “Type B” scenario, a future where business continued exactly as usual. However, the Type B scenario was constructed using blatantly absurd, highly improbable assumptions required to maintain that status quo.
By forcing leadership to confront the sheer, mathematical implausibility of uninterrupted stability, Wack forced a psychological breakthrough, prompting executives to finally accept the absolute necessity of preparing for massive disruption.
This psychological preparation paid immense operational dividends. By 1971, Shell’s scenarios explicitly mapped out the structural forces that could lead to an oil embargo. Shell utilized this mental map to implement a highly practical, costly “upgrading policy” in its refineries, championed by Jan Choufoer, thereby building the capacity to instantly convert heavy fuels into highly valuable light products (such as petrol, which had no easy substitutes). When the Yom Kippur War triggered the 1973 OPEC oil embargo, quadrupling oil prices and sending the global economy into recession, Shell was the only major oil company mentally and operationally prepared. While massive competitors scrambled in blind panic, Shell’s managers, having already rehearsed the tragedy, rapidly adjusted refinery operations and renegotiated contracts, catapulting the company from the seventh-largest oil conglomerate in the world to the second-largest.
The Shell case study perfectly encapsulates the antifragile mindset: intense discomfort is a feature of the strategic planning process, not a bug. By rehearsing tragedy and volatility in the realm of imagination, the organization acts with unprecedented speed, clarity, and precision when volatility inevitably strikes reality.
Organizational Stress-Testing Methodologies#
The following breakdown outlines four distinct methodologies for intentionally stress-testing different layers of an enterprise. By systematically targeting everything from digital infrastructure to executive decision-making, these practices build comprehensive resilience against unexpected disruptions.
Chaos Engineering
Primary Target: Technical Infrastructure
Mechanism of Action: Automated, controlled injection of digital faults (latency, server death).
Strategic Benefit: Uncovers latent software bugs; forces the building of auto-failover systems.
Game Days
Primary Target: Human Operations
Mechanism of Action: Live, simulated crisis environments test communication and protocol execution.
Strategic Benefit: Builds organizational muscle memory; removes panic from incident response.
Red Teaming
Primary Target: Strategic Defenses
Mechanism of Action: Adversarial groups explicitly attack cyber, physical, and strategic vulnerabilities.
Strategic Benefit: Exposes groupthink; forces defense mechanisms to adapt to active, intelligent threats.
Scenario Planning
Primary Target: Executive Mindset
Mechanism of Action: Constructing divergent, often uncomfortable futures to break cognitive biases.
Strategic Benefit: Pre-programs strategic responses to macro-disruptions; nullifies the shock of the unexpected.
Conclusion: The Architecture of the Antifragile Enterprise#
The architecture of global systems has reached a critical, irreversible inflection point. The multi-decade era of hyper-optimized, friction-free commerce, in which extreme efficiency was the sole metric of success and structural redundancy was ruthlessly eliminated as financial waste, has demonstrably and violently ended. The continuous, overlapping sequence of modern crises, ranging from shattered global supply chains and failures in climate infrastructure to systemic technological outages and geopolitical embargoes, has conclusively proven that highly optimized, robust systems are inherently fragile. When exposed to the realities of Knightian uncertainty, they do not bend; they break.
To architect organizations that can endure and dominate the coming decades, corporate leadership must fully embrace the counterintuitive principles of antifragility. Systems must be engineered from the ground up to expect, metabolize, and ultimately profit from continuous volatility. This requires a profound structural and cultural realignment across the entire enterprise. Global value chains must be strategically branched to ensure operational continuity, abandoning the brittle perfection of pure Just-In-Time manufacturing in favor of calculated strategic buffers. Massive financial reserves and barbell investment strategies must be maintained not as idle, inefficient capital, but as aggressive, highly potent real options waiting to be deployed during moments of peak market panic. Finally, the institutional culture itself must be perpetually stressed and challenged through the strict application of Chaos Engineering, operational Game Days, adversarial Red Teaming, and uncomfortable Scenario Planning.
By intentionally absorbing the micro-traumas of simulated failure and willingly bearing the short-term financial costs of strategic redundancy, global systems can transcend the mundane desire for mere survival. They evolve into highly adaptive, predatory organisms capable of devouring disorder, turning the chaos of the external environment into the exact fuel required for continuous, exponential growth and absolute competitive dominance.
References#
- George A. Alessandria, Shafaat Y. Khan, Armen Khederlarian, Carter B. Mix, and Kim J. Ruhl, “The Aggregate Effects of Global and Local Supply Chain Disruptions: 2020-2022,” NBER Working Paper 30849 (2023), https://doi.org/10.3386/w30849.
- Jacobs, B. W., Singhal, V. R., & Zhan, X. (2022). Stock market reaction to global supply chain disruptions from the 2018 US government ban on ZTE. Journal of Operations Management, 68(8), 903-927. https://doi.org/10.1002/joom.1197
- Ernest Liu & Yukun Liu & Vladimir Smirnyagin & Aleh Tsyvinski, 2024. “Supply Chain Disruptions, Supplier Capital, and Financial Constraints,” Cowles Foundation Discussion Papers 2402R1, Cowles Foundation for Research in Economics, Yale University.
- Liu, E., Liu, Y., Smirnyagin, V., & Tsyvinski, A. (2025). Supply chain disruptions, supplier capital, and financial constraints.
- ShakirUllah, G, Huaccho Huatuco, LD and Burgess, TF (2014) A Literature Review of Disruption and Sustainability in Supply Chains. In: KES Transactions on Sustainable Design and Manufacturing, Special Edition - Sustainable Design and Manufacturing 2014. International Conference on Sustainable Design and Manufacturing 2014, 28-30 Apr 2014, Cardiff, UK.. KES International, pp. 500-512. ISBN: 978-0-9561516-9-8.
- Barrot, Jean-Noël & Sauvagnat, Julien. (2016). Input Specificity and the Propagation of Idiosyncratic Shocks in Production Networks. The Quarterly Journal of Economics. 131. qjw018. 10.1093/qje/qjw018.
- Cajal-Grossi, Julia & Del Prete, Davide & Macchiavello, Rocco. (2023). Supply Chain Disruptions and Sourcing Strategies. International Journal of Industrial Organization. 90. 103004. 10.1016/j.ijindorg.2023.103004.
- Inoue, H., & Todo, Y. (2023). Disruption of international trade and its propagation through firm-level domestic supply chains: A case of Japan. PLOS ONE, 18(11), e0294574. https://doi.org/10.1371/journal.pone.0294574
- Carvalho, V. M., Nirei, M., Saito, Y. U., & Tahbaz-Salehi, A. (2021). Supply Chain Disruptions: Evidence from the Great East Japan Earthquake. The Quarterly Journal of Economics, 136(2), 1255-1321. https://doi.org/10.1093/qje/qjaa044
- Acemoglu, D., Ozdaglar, A. & Tahbaz-Salehi, A., 2015. Systemic risk and stability in financial networks. American Economic Review, Volume 105, p. 564-608.
- Battiston, S. et al., 2016. The price of complexity in financial networks. Proceedings of the National Academy of Sciences, Volume 113, p. 10031-10036.
- Boehm, C. E., Flaaen, A., & Pandalai-Nayar, N., 2019. Input linkages and the transmission of shocks: Firm-level evidence from the 2011 Tōhoku earthquake. Review of Economics and Statistics, Volume 101, p. 60-75.
- Vodenska, I. et al., 2021. Systemic stress test model for shared portfolio networks. Scientific Reports, Volume 11, p. 3358.
- Zhang, H. & Doan, T. T. H., 2023. Global Sourcing and Firm Inventory During the Pandemic. s.l.:RIETI.
- Davis, Steven J., and James A. Kahn. 2008. “Interpreting the Great Moderation: Changes in the Volatility of Economic Activity at the Macro and Micro Levels.” Journal of Economic Perspectives 22 (4): 155-80.
- Dalton, John (2013): A Theory of Just-in-Time and the Growth in Manufacturing Trade.
- Bartak, J., Jabłoński, Ł., & Jastrzębska, A. (2021). Examining GDP Growth and Its Volatility: An Episodic Approach. Entropy (Basel, Switzerland), 23(7), 890. https://doi.org/10.3390/e23070890
- Jia, Y., Popova, I., Simkins, B., & Wang, Q. E. (2019). Second and higher moments of fundamentals: A literature review. European Financial Management, 26(1), 216-237. https://doi.org/10.1111/eufm.12215
- Evans, Carolyn & Harrigan, James. (2005). Distance, Time, and Specialization: Lean Retailing in General Equilibrium. American Economic Review. 95. 292-313. 10.1257/0002828053828590.
- Yan XChen LDing X(2024)Optimal Cash Management with Payables FinanceOperations Research10.1287/opre.2022.019672:5(1806-1826)Online publication date: 1-Sep-2024
- Jola-Sanchez ASerpa J(2021)Inventory in Times of WarManagement Science10.1287/mnsc.2020.380167:10(6457-6479)Online publication date: 1-Oct-2021
- Wang, Y., Yu, B., & Chen, J. (2023). Factors affecting customer intention to return in online shopping: the roles of expectation disconfirmation and post-purchase dissonance. Electronic Commerce Research, 1-35.
- Negara, S. D., & Soesilowati, E. S. (2021). E-Commerce in Indonesia: Impressive growth but facing serious challenges.
- Mukherjee, M., Loganathan, T., Mandal, S., & Saraswathy, G. (2021). Biodegradability Study of Footwear Soling Materials in Simulated Compost Environment. Journal of the American Leather Chemists Association, 116(2).
- Ntumba, C., Aguayo, S., & Maina, K. (2023). Revolutionizing Retail: A Mini Review of E-commerce Evolution. Journal of Digital Marketing and Communication, 3(2), 100-110.
- Sharma, R., Srivastva, S., & Fatima, S. (2023). E-Commerce and Digital Transformation: Trends, Challenges, and Implications. International Journal for Multidisciplinary Research (IJFMR), 5(5).
- Kasowaki, L., & Ali, S. (2024). Next-Gen Transactions: Internet Banking’s Crucial Role in Modern E-Commerce (No. 11810). EasyChair.
- Ismail, A., Hidajat, T., Dora, Y. M., Prasatia, F. E., & Pranadani, A. (2023). Leading the Digital Transformation: Evidence from Indonesia. Asadel Publisher.
- Kryvtsov, Oleksiy & Midrigan, Virgiliu, 2010. “Inventories and real rigidities in New Keynesian business cycle models,” Journal of the Japanese and International Economies, Elsevier, vol. 24(2), pages 259-281, June.
- Michael P. Keane & Susan E. Feinberg, 2007. “Advances In Logistics And The Growth of Intra‐Firm Trade: The Case Of Canadian Affiliates Of U.S. Multinationals, 1984-1995,” Journal of Industrial Economics, Wiley Blackwell, vol. 55(4), pages 571-632, December.
- Keane, Michael & Feinberg, Susan. (2009). Tariff effects on MNC decisions to engage in intra-firm and arm’s-length trade. Canadian Journal of Economics. 42. 900-929. 10.1111/j.1540-5982.2009.01532.x.
- Khan, Aubhik, and Julia K. Thomas. 2007. “Inventories and the Business Cycle: An Equilibrium Analysis of (S, s) Policies.” American Economic Review 97 (4): 1165-1188.
- Kinney, Michael & Wempe, William. (2002). Further Evidence on the Extent and Origins of JIT’s Profitability Effects. The Accounting Review. 77. 10.2308/accr.2002.77.1.203.
- Matthias Meier, 2020. “Supply Chain Disruptions, Time to Build, and the Business Cycle,” CRC TR 224 Discussion Paper Series crctr224_2020_160, University of Bonn and University of Mannheim, Germany.
- Meier, Matthias & Pinto, Eugenio. (2024). COVID-19 supply chain disruptions. European Economic Review. 162. 104674. 10.1016/j.euroecorev.2024.104674.
- Fullerton, R. R., McWatters, C. S., & Fawson, C. (2003). An examination of the relationships between JIT and financial performance. Journal of Operations Management, 21(4), 383-404. https://doi.org/10.1016/S0272-6963(03)00002-0
- Huson, M., & Nanda, D. (1995). The impact of just-in-time manufacturing on firm performance in the US. Journal of Operations Management, 12(3-4), 297-310. https://doi.org/10.1016/0272-6963(95)00011-G
- Fröhlich, M. T., & Dixon, J. R. (2001). A taxonomy of manufacturing strategies revisited. Journal of Operations Management, 19(5), 541-558. https://doi.org/10.1016/S0272-6963(01)00063-8
- Fullerton, R. R., & McWatters, C. S. (2000). The production performance benefits from JIT implementation. Journal of Operations Management, 19(1), 81-96. https://doi.org/10.1016/S0272-6963(00)00051-6
- Oberndorfer, Ulrich & Moslener, Ulf & Böhringer, Christoph & Ziegler, Andreas. (2008). Clean and Productive? Evidence from the German Manufacturing Industry. SSRN Electronic Journal. 10.2139/ssrn.1307649.
- Micah Zenko, Red Team: How to Succeed by Thinking Like the Enemy, (United States of America: Basic Books, 2015), pp. 1-23.
- Rawat, R., & Sahgal, A. (2025). “Red-Teaming for India’s Military Establishment: Concepts, Contexts, and Consequences.” ORF Occasional Paper No. 476, Observer Research Foundation
- Ortiz, Julio L., 2026. “Spread too thin: The impact of lean inventories,” Journal of Monetary Economics, Elsevier, vol. 159(C).
- Julio L. Ortiz, Constantin Bürgi (2026). Overreaction Through Anchoring. International Journal of Forecasting, 42(2), 512-526.
- Alnaim, Musaab & Kouaib, Amel. (2023). Inventory Turnover and Firm Profitability: A Saudi Arabian Investigation. Processes. 11. 716. 10.3390/pr11030716.
- Roumiantsev, Serguei & Netessine, Serguei. (2007). Inventory and Its Relationship With Profitability: Evidence From an International Sample of Countries. SSRN Electronic Journal. 10.2139/ssrn.2319862.
- Trainor, William and Cupkovic, Dan and Chhachhi, Indudeep and Brown, Christopher, Using Barbells to Lift Risk-Adjusted Return (October 1, 2020). Journal of Investment Consulting, Vol. 20, No. 1, 2020, pp. 40-47 , Available at SSRN: https://ssrn.com/abstract=3753732
- Hambusch, Gerhard; Hong, KiHoon Jimmy; Webster, Ellenora. The Journal of Fixed Income; London Vol. 25, Iss. 1, (Summer 2015): 96-111. DOI:10.3905/jfi.2015.25.1.096